Feature Scaling
Makine öğreniminde feature scaling (özellik ölçeklendirme), bir makine öğrenimi modeli oluşturmadan önce verilerin ön işlenmesi sırasında en kritik adımlardan biridir. Ölçeklendirme, zayıf bir makine öğrenimi modeli ile daha iyisi arasında bir fark yaratabilir.
Makine öğrenimi, karışık meyve suyu yapmak gibidir. En iyi karıştırılmış suyu elde etmek istiyorsak, tüm meyveleri boyutlarına göre değil, doğru oranlarına göre karıştırmamız gerekir. Benzer şekilde, birçok makine öğrenimi algoritmasında, tüm özellikleri aynı duruma getirmek için, ölçeklendirme yapmamız gerekir, böylece tek bir önemli sayı oluşturduğumuz modeli büyüklükleri nedeniyle etkileyemez.
Feature scaling işleminde en çok kullanılanlar Normalizasyon ve Standardizasyon teknikleridir.
Normalizasyonda değerlerimizi iki sayı arasında, tipik olarak [0,1] veya [-1,1] arasında sınırlamak istediğimizde normalleştirme kullanılır.
Standardizasyon, verileri sıfır ortalamaya ve 1 varyansına dönüştürürken, verilerimizi birimsiz hale getirir.
Peki neden gereklidir? Makine öğrenimi algoritması sadece sayıyı görür. Eğer aralıkta çok büyük bir fark varsa, bir tarafta farkın binler olduğunu ve diğer tarafta farkın onlar arasında değiştiğini farzedelim. Daha yüksek aralıklı sayıların bir tür üstünlüğe sahip olduğu varsayımını yapar. Dolayısıyla bu daha önemli sayı, modeli eğitirken daha belirleyici bir rol oynamaya başlar.
Makine öğrenimi algoritması sayılar üzerinde çalışır ve bu sayının neyi temsil ettiğini bilmez. 10 gramlık bir ağırlık ve 10 dolarlık bir fiyat tamamen iki farklı şeyi temsil ediyor ama makine öğrenmesi algoritması bunun farklı olduğunu anlamıyor ve model için her ikisine aynı muamelesi yapıyor.
Dolayısıyla bu daha önemli sayı, modeli eğitirken daha belirleyici bir rol oynamaya başlar. Bu nedenle, herhangi bir ön önem olmaksızın her özelliği aynı temelde getirmek için Feature Scaling “özellik ölçeklendirmesi” gereklidir. İlginç bir şekilde, ağırlığı “Kg” ye çevirirsek, “Fiyat” baskın hale gelir.
Özellik ölçeklemenin uygulanmasının bir başka nedeni de, sinir ağı gradyan descent gibi birkaç algoritmanın, özellik ölçeklendirmesi olunca global minimuma çok daha hızlı yakınlaşmasıdır.
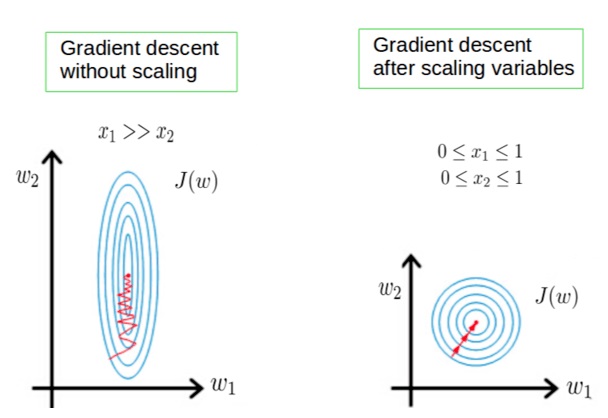
Verilerin arasındaki mesafeyi ölçen makine öğrenmesi algoritmaları için feature scaling çok önemlidir. Eğer ölçeklendirme yapılmazsa, yüksek değere sahip özellik mesafe ölçümünü domine edecektir.
Birçok algoritmada, daha hızlı yakınsama istediğimizde ölçeklendirme, sinir ağında olduğu gibi bir zorunluluktur.
Ham verilerin değer aralığı büyük ölçüde değiştiğinden, bazı makine öğrenimi algoritmalarında, nesnel işlevler normalleştirme olmadan doğru şekilde çalışmaz. Örneğin, sınıflandırıcıların çoğu iki nokta arasındaki mesafeyi mesafeye göre hesaplar. Özelliklerden biri geniş bir değer aralığına sahipse, mesafe bu belirli özelliği yönetir. Bu nedenle, tüm özelliklerin aralığı normalize edilmelidir, böylece her özellik son mesafeye yaklaşık orantılı olarak katkıda bulunur.
Yukarıda belirtildiği gibi koşullar karşılanmadığında bile, ML algoritması bir ölçek beklerse veya bir saturation fenomeni meydana gelirse, tekrar özelliklerinizi yeniden ölçeklendirmeniz gerekebilir. Yine, doyurucu aktivasyon işlevlerine (örneğin sigmoid) sahip bir sinir ağı iyi bir örnektir.
Özellik ölçeklendirmesinin önemli olduğu bazı algoritmalara bakalım.
• K-nearest neighbors (KNN) Öklid mesafe ölçüsü ile büyük değerlere duyarlıdır ve bu nedenle tüm özelliklerin eşit olarak tartılması için ölçeklendirilmelidir.
• K-Means burada Öklid mesafe ölçüsünü kullanır özellik ölçekleme önemlidir.
• Principal Component Analysis(PCA) gerçekleştirilirken ölçeklendirme çok önemlidir. PCA, feature(özellikleri) maksimum varyansla elde etmeye çalışır ve varyans, yüksek büyüklükteki özellikler için yüksektir ve PCA’yı yüksek büyüklük özelliklerine doğru çarpıtır.
• Gradient Descent’i ölçeklendirerek hızlandırabiliriz çünkü küçük aralıklarda hızlı ve büyük aralıklarda yavaşça iner ve değişkenler çok düzensiz olduğunda verimsiz bir şekilde optimum seviyeye iner.
Normalleştirme / ölçeklendirme gerektirmeyen algoritmalar, kurallara bağlı olanlardır. Değişkenlerin herhangi bir monoton dönüşümünden etkilenmezler. Ölçeklendirme, tekdüze bir dönüşümdür. Bu kategorideki algoritmaların örnekleri, tüm tree-tabanlı algoritmalardır. Bunlar CART, Random Forests, Gradient Boosted Decision Trees. Bu algoritmalar kuralları kullanır(eşitsizlikler dizisi) ve normalleştirme gerektirmez.
Linear Discriminant Analysis(LDA), Naive Bayes gibi algoritmalar bu durumu işlemek ve özelliklere göre ağırlık vermek için donatılmış tasarımlara sahiptirler.Bu algoritmalarda özellik ölçeklendirmesinin gerçekleştirilmesinin çok fazla etkisi olmayabilir.
Dikkat edilmesi gereken birkaç önemli nokta:
• Ortalama merkezleme kovaryans matrisini etkilemez.
• Değişkenlerin ölçeklendirilmesi kovaryans matrisini etkiler.
• Standardizasyon kovaryansı etkiler.
Feature Scaling Yöntemleri
- Min-Max Scaler
- Standard Scaler
- Max Abs Scaler
- Robust Scaler
- Quantile Transformer Scaler
- Power Transformer Scaler
- Unit Vector Scaler
Bu yöntemleri elimizdeki küçük veri seti ile açıklamaya başlayalım.
1 | import pandas as pd |
WEIGHT PRICE
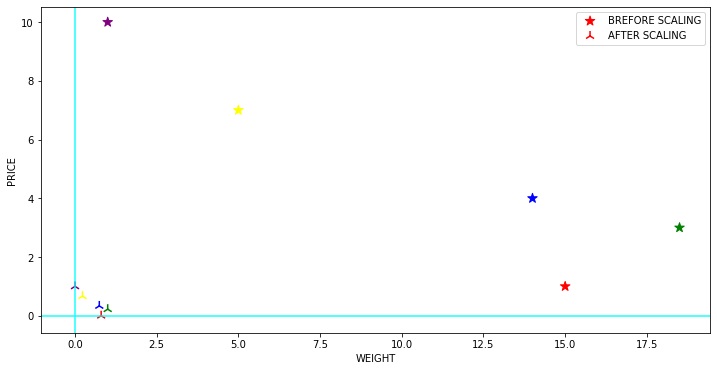
Pineapple 15.0 1
Apple 18.5 3
Strawberry 14.0 4
Watermelon 5.0 7
Fig 1.0 101)Min-Max scaler
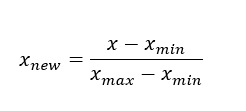
Min-max Scaler verilen aralığa göre özellikleri ölçekler. Bu tahmin aracı, her özelliği, eğitim setinde verilen aralıkta, örneğin sıfır ile bir arasında olacak şekilde tek tek ölçeklendirir ve çevirir. Bu ölçekleyici, negatif değerler varsa -1 ile 1 aralığında verileri küçültür. Aralığı [0,1] veya [0,5] veya [-1,1] gibi ayarlayabiliriz. Bu Ölçekleyici, standart sapma küçükse ve dağılım Gaussian değilse iyi sonuç verir. Min-max scaler, aykırı değerlere karşı hassastır.
1 | from sklearn.preprocessing import MinMaxScaler |
2) Standard Scaler
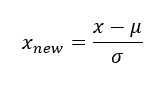
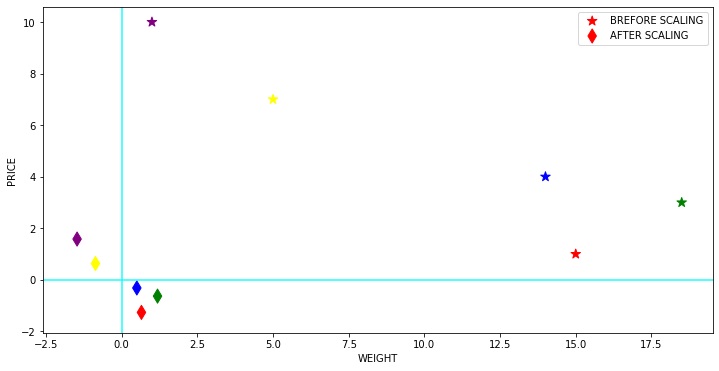
Standart Scaler, verilerin normal olarak her bir özelliğe dağıtıldığını varsayar ve bunları, 1’lik bir standart sapma ile dağıtım 0 civarında ortalanacak şekilde ölçeklendirir.
Merkezleme ve ölçeklendirme, training setideki örnekler üzerindeki ilgili istatistikleri hesaplayarak her özellik için bağımsız olarak gerçekleşir. Veriler normal olarak dağıtılmıyorsa, bu kullanılacak en iyi ölçekleyici değildir.
1 | from sklearn.preprocessing import StandardScaler |
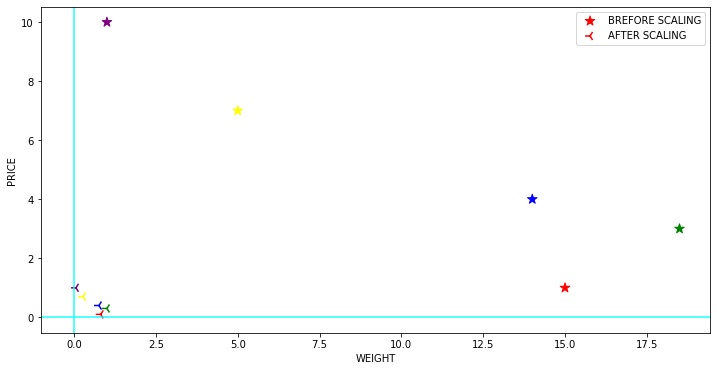
3) Max Abs Scaler
Max Abs Scaler her özelliği maksimum mutlak değerine göre ölçekler. Bu ölçekleyici, eğitim setindeki her bir özelliğin maksimum mutlak değeri 1.0 olacak şekilde her özelliği ayrı ayrı ölçeklendirir ve çevirir. Verileri kaydırmaz, ortalamaz ve dolayısıyla herhangi bir seyrekliği yok etmez.
Yalnızca pozitif verilerde, bu ölçekleyici Min-Maks ölçekleyiciye benzer şekilde davranır ve bu nedenle önemli aykırı değerlerin varlığından da muzdariptir.
1 | from sklearn.preprocessing import MaxAbsScaler |
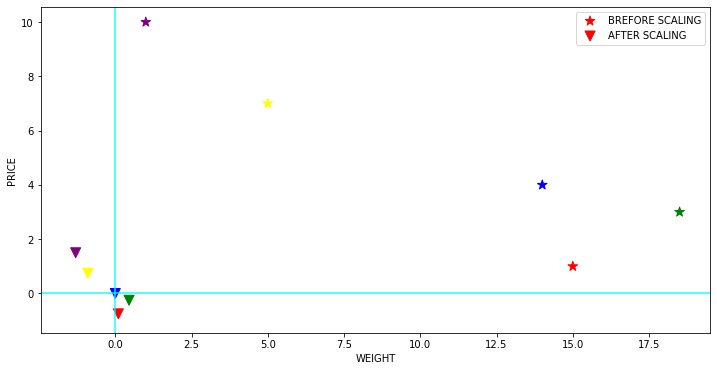
4) Robust Scaler
Bu ölçekleyici aykırı değerlere karşı sağlamdır. Verilerimiz çok sayıda aykırı değer içeriyorsa, verilerin ortalamasını ve standart sapmasını kullanarak ölçeklendirme iyi sonuç vermeyecektir.
Bu ölçekleyici medyanı kaldırır ve verileri nicelik aralığına göre ölçeklendirir ( IQR: Çeyrekler Arası Aralık). IQR, 1. çeyrek (25.inci kuantil) ile 3. çeyrek (75.inci kuantil) arasındaki aralıktır. Bu ölçekleyicinin merkezleme ve ölçeklendirme istatistikleri yüzdelik dilimlere dayanmaktadır ve bu nedenle birkaç sayıdaki büyük marjinal aykırı değerlerden etkilenmez. Aykırı değerlerin kendilerinin dönüştürülmüş verilerde hala mevcut olduğuna unutmayın. Ayrı bir aykırı değer kırpılması isteniyorsa, doğrusal olmayan bir dönüşüm gereklidir.
1 | from sklearn.preprocessing import RobustScaler |
Şimdi bir aykırı değer sunarsak ve Standart Scaler ve Robust Scaler kullanarak ölçeklendirmenin etkisini görürsek ne olacağını görelim (karo şekil aykırı değeri gösterir).
1 | dfr = pd.DataFrame({'WEIGHT': [15, 18, 12,10,50], |
WEIGHT PRICE
Apricot 15 1
Apple 18 3
Banana 12 2
Grape 10 5
Cherry 50 20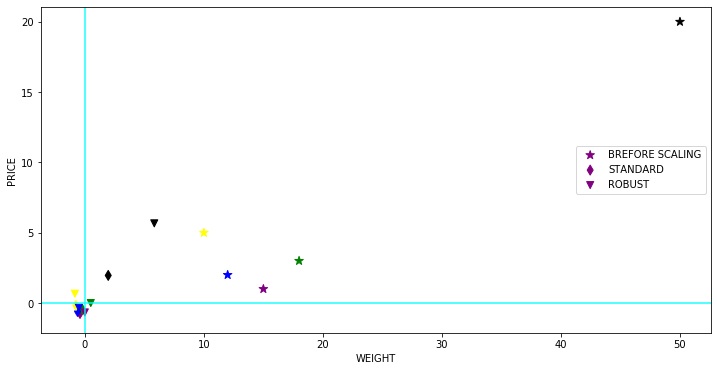
5) Quantile Transformer Scaler
Nicelik bilgilerini kullanarak özellikleri dönüştürür. Bu yöntem, özellikleri tek tip veya normal bir dağılım izleyecek şekilde dönüştürür. Bu nedenle, belirli bir özellik için, bu dönüşüm en sık görülen değerleri yayma eğilimindedir. Aynı zamanda (marjinal) aykırı değerlerin etkisini de azaltır: bu nedenle bu, Robust bir preprocessing şemasıdır. Bir özelliğin kümülatif dağılım işlevi, orijinal değerleri yansıtmak için kullanılır. Bu dönüşümün doğrusal olmadığını ve aynı ölçekte ölçülen değişkenler arasındaki doğrusal korelasyonları bozabileceğini, ancak farklı ölçeklerde ölçülen değişkenleri daha doğrudan karşılaştırılabilir hale getirdiğini unutmayın. Bu aynı zamanda bazen Rank Scaler olarak da adlandırılır.
1 | from sklearn.preprocessing import QuantileTransformer |
C:\Users\kader\Anaconda3\lib\site-packages\sklearn\preprocessing\data.py:2239: UserWarning: n_quantiles (1000) is greater than the total number of samples (5). n_quantiles is set to n_samples.
% (self.n_quantiles, n_samples))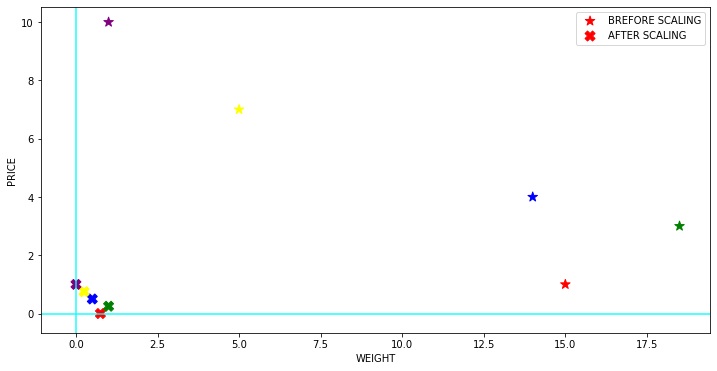
6)Power Transformer Scaler
Parametrik, monoton dönüşümler ailesinden olan Power Transformatörü, verileri daha Gaussian benzeri hale getirmek için uygulanır. Bu yöntem, aralık boyunca eşit olmayan bir değişkenin değişkenliği (farklı varyans) veya normalliğin istendiği durumlar ile ilgili sorunları modellemek için yararlıdır.
Power Transformatörü, maksimum olasılık tahmini yoluyla varyansı stabilize etmede ve çarpıklığı en aza indirmede optimum ölçeklendirme faktörünü bulur.
Şu anda, PowerTransformer’ın Sklearn uygulaması Box-Cox transformu ve Yeo-Johnson transformu desteklemektedir. Varyansı sabitlemek ve çarpıklığı en aza indirmek için en uygun parametre maksimum olasılıkla tahmin edilir. Box-Cox, giriş verilerinin kesinlikle pozitif olmasını gerektirirken, Yeo-Johnson hem pozitif hem de negatif verileri destekler.
1 | from sklearn.preprocessing import PowerTransformer |
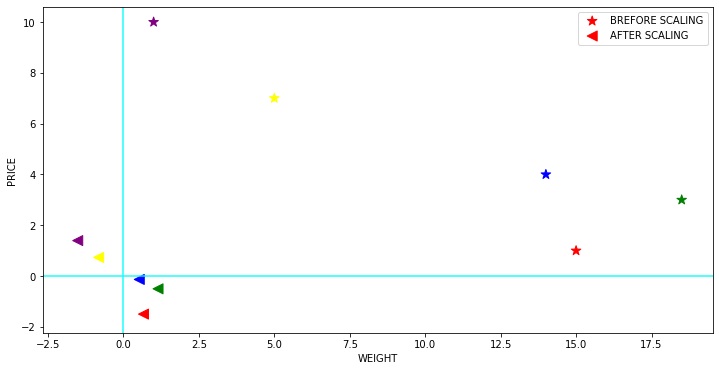
7) Unit Vector Scaler
Ölçeklendirme, bütün özellik vektörünün birim uzunluk olduğu düşünülerek yapılır. Bu genellikle her bileşeni vektörün Öklid uzunluğuna (L2 Normu) bölmek anlamına gelir. Bazı uygulamalarda (örn. histogram özellikleri), özellik vektörünün L1 normunu kullanmak daha pratik olabilir.
- L1 normu, oldukça açık nedenlerden dolayı L2 normundan daha sağlamdır: L2 normunun kareleri değerleri, dolayısıyla aykırı değerlerin maliyetini üssel olarak artırır; L1 normu yalnızca mutlak değeri alır, bu nedenle onları doğrusal olarak değerlendirir.
Min-Maks ölçeklendirmede olduğu gibi, birim vektör tekniği [0,1] aralığında değerler üretir. Katı sınırları olan özelliklerle uğraşırken bu oldukça kullanışlıdır. Örneğin, görüntü verileriyle uğraşırken renkler yalnızca 0 ile 255 arasında değişebilir.
1 | ## Unit vector with L1 norm |
| WEIGHT | PRICE | |
|---|---|---|
| Pineapple | 0.280374 | 0.04 |
| Apple | 0.345794 | 0.12 |
| Strawberry | 0.261682 | 0.16 |
| Watermelon | 0.093458 | 0.28 |
| Fig | 0.018692 | 0.40 |
1 | ## Unit vector with L2 norm |
| WEIGHT | PRICE | |
|---|---|---|
| Pineapple | 0.533930 | 0.075593 |
| Apple | 0.658513 | 0.226779 |
| Strawberry | 0.498334 | 0.302372 |
| Watermelon | 0.177977 | 0.529150 |
| Fig | 0.035595 | 0.755929 |
Aşağıdaki diyagram, verilerin tüm farklı ölçekleme teknikleri için nasıl yayıldığını ve görebileceğimiz gibi, birkaç noktanın üst üste geldiğini, dolayısıyla ayrı ayrı görünmediğini göstermektedir.
1 | dfr = pd.DataFrame({'WEIGHT': [15, 18, 12,10,50], |
WEIGHT PRICE
Apricot 15 1
Apple 18 3
Banana 12 2
Grape 10 5
Cherry 50 20
C:\Users\kader\Anaconda3\lib\site-packages\sklearn\preprocessing\data.py:2239: UserWarning: n_quantiles (1000) is greater than the total number of samples (5). n_quantiles is set to n_samples.
% (self.n_quantiles, n_samples))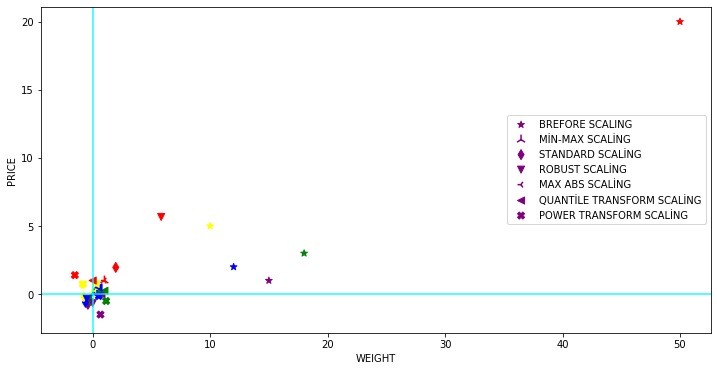
Feature Scaling, Makine öğrenimi pre-processing kısmında önemli bir adımdır. Derin öğrenme, daha hızlı yakınsama için feature scaling gerektirir ve bu nedenle hangi feature scaling yöntemini kullanılacağına karar vermek çok önemlidir. Çeşitli algoritmalar için ölçeklendirme yöntemlerinin birçok karşılaştırma araştırması vardır. Yine de, diğer makine öğrenimi adımlarının çoğu gibi, özellik ölçeklendirme de bir deneme yanılma sürecidir.